

Fem frågor och svar om Leasifys onboarding
Nyfiken på hur Leasifys onboardingprocess fungerar? I denna artikel svarar vår Onboarding Manager, Theodor Röhr, på de fem vanligaste frågorna nya...
1 min read
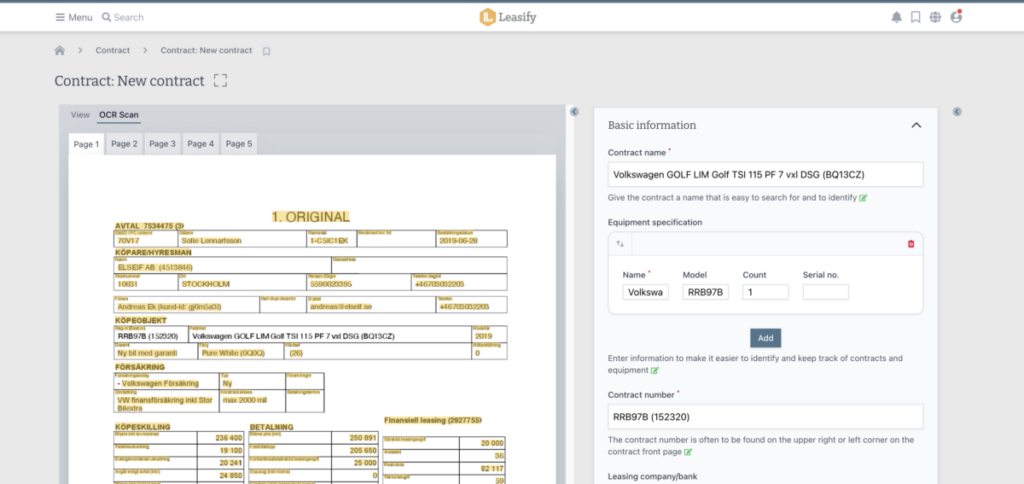
Optisk teckenigenkänning (OCR) är särskilt användbart för PDF-dokument eftersom det gör det möjligt att omvandla inskannad text till redigerbar och sökbar information. Med OCR kan du enkelt söka efter specifika ord eller fraser i dokumentet, kopiera och klistra in innehåll i andra program, eller redigera texten direkt utan att behöva skriva om den manuellt. Det sparar både tid och arbete – särskilt vid hantering av större mängder dokument och gör det enklare att återanvända och bearbeta innehållet på ett smidigt sätt.
Amazon Textract är en maskininlärningstjänst som används för att extrahera text och data från olika typer av dokument, inklusive PDF-filer. Tjänsten använder OCR-teknik för att identifiera och hämta text, men kan även känna igen och extrahera information från tabeller och formulär. Med Textract kan du automatisera datainsamlingen från dokument, vilket sparar tid och minskar risken för fel. Tjänsten är utformad för att vara enkel att använda – ingen erfarenhet av maskininlärning krävs. Du kan använda Textract för att extrahera text och data från dokument som lagras i Amazon S3, eller integrera Textract i egna applikationer via API.
Modellträning är processen där en maskininlärningsmodell lär sig att förutsäga eller fatta beslut utifrån data. Under träningen får modellen ta del av ett dataset som innehåller både indata och de korrekta utfallen. Genom att jämföra modellens egna förutsägelser med de faktiska resultaten beräknas ett felvärde, som i sin tur används för att justera modellens parametrar. Målet är att successivt minska felet och därmed öka träffsäkerheten – en process som kallas optimering. Träningen pågår tills modellen uppnår önskad noggrannhet eller tills förbättringen avtar. När modellen är färdigtränad kan den användas för att analysera ny, tidigare osedd data.
I Leasifys tjänst kombineras tre tekniker – OCR, Amazon Textract och modellträning – för att automatiskt identifiera och extrahera viktig information ur PDF-dokument vid onboarding. Maskininlärning används även för att föreslå var olika fält i dokumentet bör placeras i kontraktsdatabasen, vilket sparar tid och minskar behovet av manuell hantering.
Tveka inte att kontakta oss om du har fler frågor om AI-funktionerna i vår tjänst. Välkommen!

Nyfiken på hur Leasifys onboardingprocess fungerar? I denna artikel svarar vår Onboarding Manager, Theodor Röhr, på de fem vanligaste frågorna nya...

När man överväger att hyra/leasa utrustning, se till att du gör dina läxor för att förhandla till de bästa villkoren för din verksamhet. Equipment...

Leasify når en viktig milstolpe – för första gången redovisar bolaget ett positivt resultat. Genom en framgångsrik SaaS-modell, en växande kundbas...