

True-cloud access for IFRS 16 and Local GAAP – with single sign-on
Many companies face security risks with logins where email and password credentials can easily be compromised. This is where Leasify’s Single Sign-On...
1 min read
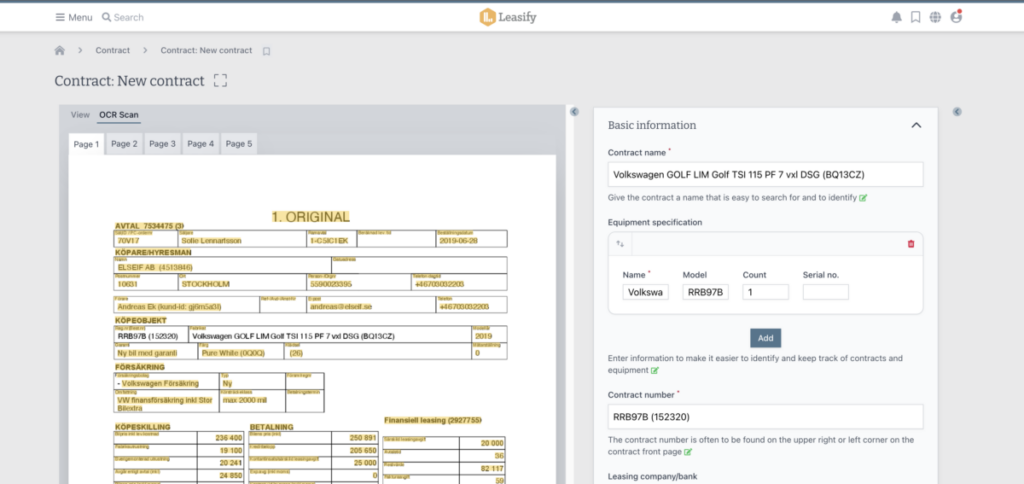
Optical Character Recognition (OCR) scanning can be useful for PDF documents because it allows you to extract text from the document and use it in other applications. This can be helpful if you need to search for a specific word or phrase within the document, or if you want to copy and paste the text into a different document. OCR scanning can also make it easier to edit the text in the document, as you can simply make changes to the text in the other application and then save the edited version of the document. OCR scanning can save you time and effort compared to manually retyping the text from the document.
Amazon Textract is a machine learning service that can be used to extract text and data from a variety of document types, including PDFs. It uses OCR technology to identify and extract text from documents, and it can also identify and extract data from tables and forms. Textract can be used to automate the process of extracting data from documents, which can save time and reduce the risk of errors. It is designed to be easy to use, with no machine learning expertise required. You can use Textract to extract text and data from documents stored in Amazon S3, or you can use the Textract API to integrate Textract with your own applications.
Model training is the process of teaching a machine learning model to make predictions or decisions based on data. During model training, the model is presented with a set of training data, which includes input data and the corresponding correct output. The model makes predictions based on the input data, and the error between the predicted output and the correct output is calculated. This error is used to update the model's parameters so that it can make more accurate predictions on future data. The process of updating the model's parameters is known as optimization. Model training continues until the model's error is below a certain threshold or until the model's performance on the training data stops improving. Once the model is trained, it can be used to make predictions or decisions on new, unseen data.
The Leasify system uses these three techniques (OCR, Textract and model training) to extract important information from PDF documents when onboarding documents. We also use machine learning to suggest where the fields in a PDF document should be placed in the contract database.
Example of OCR Scanning in the Leasify system

Many companies face security risks with logins where email and password credentials can easily be compromised. This is where Leasify’s Single Sign-On...

Planning ahead is crucial for making the right decisions and driving business growth. Without a clear overview of costs and assets, predicting...

Leasify was founded in 2015 to digitalize the leasing industry and streamline procurement processes for businesses. With the introduction of the new...